why did i build this?
over the summer of 2024, i interned at a stealth startup where i was fully responsible for a vector database migration task. we stored our semantic index on chromaDB and the entire thing had to be moved over to lanceDB. before choosing lanceDB, i had to perform a complete case study / vendor analysis to choose the right kind of vector database for our use case. this single case study got me super interested in how vector DBs work under the hood, and that sparked this entire three month journey.
inspiration
initially, i kinda wanted to build a CLI tool that could index my entire machine in a vector database. i could then easily perform semantic search to find anything i needed lol.
how did i get started?
i looked at this particular blog from scyllaDB about log strucutred merge trees to see how databases store data. after understanding how in memory memtables and on disk SSTables work together to store data, i decided to build these two out from scratch.
skiplists
skiplists are the underlying data structure i used to store my keys. they are super fascinating in how they store each node with different sparsities for different levels. this is a super neat example on how they work.
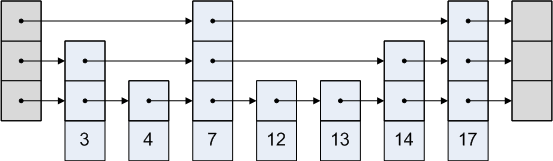
the upper levels do not have many elements, but as we move lower and lower, the density of elements incerases. this significantly improves search times . if an element is found at any of the upper levels, we can assume that the key is present in the database .
bringing it all together
using skiplists as the underlying data structure for the memtables and SSTables, it was easy to implement the basic operations.
put,get, delete, exists and search.
embeddings
everytime a value is stored (using the put operation) in the data store, i generate embeddings for the value and store it along with the user input.
currently there aree three models integrated into ghastly,
- openai's text-embedding-3-small
- colBERT's colBERT-ir/v2 (this runs locally btw)
- NVidia's NVEmbed/v2
for openai and nvidia, you'll need API keys. but colBERT can locally (like how many other vectorDBs do, ex: LanceDB) run. when you issue a search operation, ghasrtly performs vector search on these stored embeddings giving you a result set sorted by score
my adventures with local inference
honestly, getting local inference to run was an absolute blast. i got to explore a lot of Go libraries that enabled me to run huggingfadce pipelienes locally. i looked at github user sugarme's transformers library and knights-analytics' hugot. i settled on hugot because it was super straightforward. their README is also pretty neat which helped me get everything running.
the end poduct
once this was all done, i exposed a gRPC and HTTP API for all of the operations, and created a Dockerfile (to easily manage dependecies). simply running this container will give you a pretty lightweight yet efficient vector database to perform semantic search.
it's deployed on heroku, and available for use at ghastlydb.xyz. the code is also open-source, feel free to check it out. (and maybe give it a star! :)) this was a fantastic three month journey culminating in 6k lines of code and definitely more than 42 commits (stats from github) because i'm a squash and merge typa dude haha.
thanks for reading!
p.s: i'm very bad at writing so pls bear with me. i'm going to work on it.